Materialsammlung Psychologische Forschungsmethoden
Topic outline
-
Dieser Kurs soll dich bei deinem empirischen Forschungsvorhaben vertieft unterstützen und ist auf die Lehre in den Psychologiestudiengängen an der Universität Kassel abgestimmt. Bei Fragen steht dir die (studentische) Methodenberatung des Fachgebiets Psychologische Forschungsmethoden zur Verfügung. Grundlegende Kenntnisse der Verfahren werden vorausgesetzt, wir geben aber auch wiederholende und ergänzende Literaturhinweise sowie kommentierte Code-Beispiele in R.Hinweise zur Navigation:
- Klick einfach auf die Überschriften unter "Übersicht über die Themen", zu denen du dich informieren willst. Du kannst auch in der Seitenleiste links navigieren.
- Nach Begriffen suchen kannst du, indem du alles ausklappst (rechts oben) und mit Strg + F (Windows) oder cmd + F (Mac) nach Begriffen suchst.
- Öffne Textseiten in neuem Tab über Rechtsklick + Öffnen in neuem Tab, um einfach und ohne Laden wieder zurückzunavigieren.
Wir haben auch eine Checkliste für Empras und Abschlussarbeiten und für die Präregistrierung erstellt.
-
-

Datenanalyse mit...
- Non-parametrische Tests, Ordinalskalierte Variablen
- t-Tests und ANOVA
- Regression, Moderation
- Mediation, Pfadmodelle, Strukturgleichungsmodelle
- Logistische Regression
- Faktoranalyse
- Multilevelmodelle
- Interpretation Modellparameter Beispiele
- Meta-Analyse
- Systematisches Review
- Qualitative Inhaltsanalyse
-
-
-
 Was ist das?
Was ist das?
Vor jedem empirischen Forschungsvorhaben sollte eine Präregistrierung der zu testenden Hypothesen und des Versuchsdesigns sowie des Analyseplans vorgenommen werden. Nur dann kann das Forschungsvorhaben als konfirmatorisch gelten. Das ist insbesondere aus einer Open Science Perspektive heraus wichtig.Außerdem kann es sehr hilfreich sein, schon bei der Planung die finale Datenanalyse im Kopf zu behalten. So können Fehler schon direkt im Versuchsplan vermieden werden, die sonst erst später bei der Datenanalyse auffallen würden.Hier findest du nützliche Onlinetools und Hinweise zur Präregistrierung.
-
-
-

Was ist das?
Ob du kausale Schlüsse aus deinem Modell ziehen kannst, kommt insbesondere auf das Versuchsdesign sowie inhaltliche Überlegungen an. Es ist sinnvoll, sich hierzu schon bei der Planung Gedanken zu machen.
-
-
↳ Hier erfährst du unter anderem etwas über Confounder, Mediatoren und Collidervariablen.
-
-
-
-
-
 Was? Welche Frage wird beantwortet?Wie groß muss meine Stichprobe sein, damit ich eine realistische Chance habe, einen Effekt einer bestimmten Größe zu finden, sofern dieser wirklich in der Population vorliegt?Wann?Eine Poweranalyse ist nur vor der Datenanalyse zur Planung der Erhebung sinnvoll, niemals danach (post-hoc) auf Basis des beobachteten Effekts (siehe z.B. Hoening & Heisey, 2001).
Was? Welche Frage wird beantwortet?Wie groß muss meine Stichprobe sein, damit ich eine realistische Chance habe, einen Effekt einer bestimmten Größe zu finden, sofern dieser wirklich in der Population vorliegt?Wann?Eine Poweranalyse ist nur vor der Datenanalyse zur Planung der Erhebung sinnvoll, niemals danach (post-hoc) auf Basis des beobachteten Effekts (siehe z.B. Hoening & Heisey, 2001).
-
-
-

Was? Welchen Zweck erfüllt die Datenaufbereitung?Wie bekomme ich meine erhobenen Daten in eine Form, die es mir erlaubt (inferenz-)statistische Verfahren anzuwenden?
Wann? Welche Art von Umformungen werden typischerweise gemacht?
- Möglicherweise möchtest du nur ein Subset des erhobenen Datensatzes auswerten. Wir zeigen dir, wie du bestimmte Variablen oder auch bestimmte Werte nach Erfüllung von Bedingungen auswählen kannst. Wir zeigen dir auch, wie du fehlende Werte in deinen Daten finden und ggf. ausschließen kannst.
- Für unterschiedliche Analysen benötigt R die Daten in unterschiedlicher Anordnung (z.B. häufig long format für ANOVA vs. wide format für Regressionen). Wir zeigen dir, wie du zwischen unterschiedlichen Anordnungen der Daten wechseln kannst.
- In Analysen, Tabellen oder Abbildungen werden häufig statistische Kennwerte (z.B. Mittelwerte & Standardabweichungen) abgebildet. Wir zeigen dir, wie du statistische Kennwerte für unterschiedliche Gruppen (Kombinationen von Variablenausprägungen) einfach berechnen kannst.
- Möglicherweise möchtest du nur ein Subset des erhobenen Datensatzes auswerten. Wir zeigen dir, wie du bestimmte Variablen oder auch bestimmte Werte nach Erfüllung von Bedingungen auswählen kannst. Wir zeigen dir auch, wie du fehlende Werte in deinen Daten finden und ggf. ausschließen kannst.
-
-
-
-
Die aktuellsten Versionen von Cheat Sheets findest du außerdem auf der posit-Homepage (ehemals RStudio).
-
CheatSheets Datenaufbereitung
-
-
-
-
-
-
 Was? Welche Frage beantwortet das Modell?Gibt es Gruppenunterschiede/ Unterschiede zwischen Experimentalbedingungen/ Gruppen auf einem Kriterium?
Was? Welche Frage beantwortet das Modell?Gibt es Gruppenunterschiede/ Unterschiede zwischen Experimentalbedingungen/ Gruppen auf einem Kriterium?
Wann? Welche Art von Daten werden damit analysiert?
- Kriterium stetig
- Prädiktoren (hier auch Faktoren genannt) kategorial (Kategorien = Faktorstufen/Gruppen)
-
-
↳ Hier erfährst du etwas zu abhängigen und unabhängigen Faktoren, Faktorstufen, Balanciertheit und der generellen Benennung von ANOVA Designs.
-

-
-
-
↳ Hier erfährst du etwas zu Voraussetzungen und Störeinflüssen bei t-Tests und ANOVAs und wie du mit deren Verletzung umgehen kannst
-
↳ Hier erfährst du etwas zu Cohens d, (partial) eta squared und generalized eta squared
-
Wann ist eine Alphafehler Korrektur sinnvoll, welche Arten von multiplen Testen gibt es?
-
-
-
-
 Möchtest du dein ANOVA-Wissen vertiefen und testen?Hier findest du verschiedene Zusammenfassungen und kleine Aufgaben.
Möchtest du dein ANOVA-Wissen vertiefen und testen?Hier findest du verschiedene Zusammenfassungen und kleine Aufgaben. -
Wenn du deine ANOVA-Skills komplett auffrischen möchtest, dann findest du hier eine Übersicht über:
- Einfaktorielle Varianzanalyse für unabhängige Stichproben
- Zweifaktorielle Varianzanalysen für unabhängige Stichproben
- ANOVA für abhängige Stichproben
Navigiere mit den kleinen Pfeiltasten! - Einfaktorielle Varianzanalyse für unabhängige Stichproben
-
-
-
-

Was? Welche Frage beantwortet das Modell?
Kann ich mit einem oder mehreren Prädiktoren ein Kriterium vorhersagen?
Besteht ein Zusammenhang zwischen zwei Variablen, wenn man für den Einfluss anderer Variablen kontrolliert?
Moderiert eine Variable den Zusammenhang zwischen zwei anderen Variablen (Interaktion)?Wann? Welche Art von Daten werden damit analysiert?
- AV stetig
- UV(s) kategorial oder stetig
-
-
-
-
↳ Hier erfährst du etwas zu Multikollinearität und einflussreichen Datenpunkten (z.B. Ausreißer- und Extremwerte)
-
↳ hier Erfährst du etwas darüber wie Messfehler deine Ergebnisse von der Multiplen Regression verzerren können
-
Hier erfährst du etwas über Schrittweise Regression und Best-Subset Selection und Commonality-Analyse
-
-
-
-
-
-

Was? Welche Frage beantwortet das Modell?
Kann ich komplexere Zusammenhänge zwischen mehreren Variablen modellieren?
Ist der Zusammenhang von einem Prädiktor auf ein Kriterium durch einen Mediator vermittelt?Wann? Welche Art von Daten werden damit analysiert?
- AV(s) kategorial oder stetig
- UVs kategorial oder stetig
-
-
↳ Die Voraussetzungen/Störfaktoren für das Pfadmodell gleichen denen in der linearen Regression (Linearitätsannahme, Unabhängigkeit und Homoskedastizität und Normalverteilung der Residuen), nur dass die korrekte Spezifikation des Modells noch zentraler ist (= keine fehlenden Variablen und Pfade).
-
↳ Hier erfährst du etwas zu Multikollinearität und einflussreichen Datenpunkten (z.B. Ausreißer- und Extremwerte).
-
-
-
-
-
-

Was? Welche Frage beantwortet das Modell?
Konfirmatorische Faktorenanalyse: Überprüfung einer vorab spezifizierten Faktorstruktur von Items
Exploratorische Faktorenanalyse: Auffinden einer vorab nicht spezifizierten Faktorstruktur von ItemsWann? Welche Art von Daten werden damit analysiert?
Mehrere einzelne Items, die als Indikatoren für latente Konstrukte (Faktoren) dienen
-
-
-

Was? Welche Frage beantwortet das Modell?
Erweiterung des ALM für hierarchisch strukturierte Daten:
Gibt es Unterschiede in Effekten zwischen verschiedenen Level-2-Einheiten? Wodurch kann man die Unterschiede erklären?
Gibt es verschiedene Effekte auf Level-1 und Level-2 (Kontexteffekte)?
-
-
Hier findest du auch Infos zur R-Fehlermeldung "singular fit".
-
-
-
-
-

Du hast Ergebnisse einer Modellschätzung vorliegen und fragst dich, wie du sie inhaltlich korrekt interpretierst?
Für die korrekte Interpretation ist es wichtig, dass du die wesentlichen Eigenschaften des Modells und der verwendeten Daten kennst. Denn je nach Fall ändert sich die Interpretation der Parameter.
Fragen, die du dir vor der Interpretation stellen (und beantworten) solltest:
• Kategoriale und / oder metrische Prädiktoren?
• Einfache, multiple oder moderierte Regression?
• Zentrierung oder Standardisierung metrischer Prädiktoren?
• Hierarchische Daten?
• Binäres oder metrisches Kriterium?
Im Folgenden findest du Beispiele für verschiedene Fälle und passende Interpretationen.
-
-
-

Was? Welche Frage beantwortet das Modell?
Gibt es über mehrere Studien hinweg einen Gesamteffekt? Woran liegt es, dass sich Studienergebnisse (systematisch) unterscheiden?Wann? Welche Art von Daten werden damit analysiert?
- Stichprobe: Studien
- Kriterium: Vergleichbares Effektstärkemaß
- Stichprobe: Studien
-
-
-

Was? Welche Frage beantwortet das Modell?
Welcher Stand der Forschung liegt vor? Welche Studien sind bisher zu meiner Fragestellung erschienen?Wann? Welche Art von Daten werden damit analysiert?
- Alle relevanten Studien zum Thema (nicht unbedingt quantitativ vergleichbar).
Stichprobe sind Einzelstudien.
- Alle relevanten Studien zum Thema (nicht unbedingt quantitativ vergleichbar).
-
-
-

Es gibt viele verschiedene qualitative Methoden - hier gibt es nur ein Überblick über die in der Psychologie gängigste - die inhaltlich-strukturierende Inhaltsanalyse (siehe Schreier, 2014), die an der Universität Kassel im Bachelor gelehrt wird.
Was? Welche Frage beantwortet das Modell?
Fragestellungen können offener, explorativer, prozessbezogener, individualisierter, kontextualisierter, sprachbezogener, ... sein, als bei quantitativen Analysen.Wann? Welche Art von Daten werden damit analysiert?
Text verschiedenster Art: Transkribierte Interviews, Freitextantworten, Instagramcaptions, Zeitungsartikel, ...
-
-
-
 Was? Welchen Zweck erfüllen Grafiken und Tabellen?Wie kann ich meine Ergebnisse ökonomisch darstellen und damit die im Text beschriebenen Ergebnisse untermauern/verdeutlichen?
Was? Welchen Zweck erfüllen Grafiken und Tabellen?Wie kann ich meine Ergebnisse ökonomisch darstellen und damit die im Text beschriebenen Ergebnisse untermauern/verdeutlichen?
Wann? Welche Ergebnisse kann ich wie darstellen (Grafiken vs. Tabellen vs. im Text)?
- Die zentralen Ergebnisse deiner empirischen Arbeit, auf die du dich in der Diskussion und bei deinen Schlussfolgerungen beziehst, solltest du explizit im Text benennen und beschreiben (Achtung: auch für das Berichten
von statistischen Ergebnissen gibt es Regeln). Dabei solltest du dich auch auf Tabellen und Grafiken beziehen,
die diese Ergebnisse zur Verdeutlichung darstellen.
- Tabellen können der übersichtlichen Darstellung einer Vielzahl bzw. der Gesamtheit von Ergebnissen dienen, die nicht alle zwangsläufig relevant genug sind, um im Text Erwähnung zu finden (z.B. Parameter des gesamten (Regressions-/ANOVA-) Modells). Tabellen können auch die Reproduzierbarkeit von Ergebnissen ermöglichen (z.B. Werte aus Einzelstudien in Metaanalysen oder Kovarianzmatrizen (& Mittelwerte) für Faktorenanalysen, ...).
- Grafiken können dir an unterschiedlichen Stellen im Forschungsprozess helfen. Grafiken
können dir bei der Auswertung deiner erhobenen Daten helfen (z.B. Verteilungen plotten, Ausreißer identifizieren, ...) oder Leser*innen beim Verständnis deiner zentralen Ergebnisse in deiner Arbeit helfen. Oft ist die graphische
Darstellung deiner Ergebnisse leichter verständlich als die Beschreibungen im Text.
- Denke auch daran, dass es für die Gestaltung und Einbettung von Grafiken & Tabellen in den Text bestimmte Regeln gibt (üblicherweise APA Style).
- Die zentralen Ergebnisse deiner empirischen Arbeit, auf die du dich in der Diskussion und bei deinen Schlussfolgerungen beziehst, solltest du explizit im Text benennen und beschreiben (Achtung: auch für das Berichten
von statistischen Ergebnissen gibt es Regeln). Dabei solltest du dich auch auf Tabellen und Grafiken beziehen,
die diese Ergebnisse zur Verdeutlichung darstellen.
-
-
-
Wie verwende ich diesen Kursabschnitt?
- Wenn du noch nie mit ggplot2 gearbeitet hast, solltest du zuerst das Step-by-Step Tutorial durchklicken. Dabei bauen wir gemeinsam ein Liniendiagramm zur Darstellung von Mittelwerten (inklusive Fehlerbalken) Schritt für Schritt auf. Wir starten mit einem konkreten Datenbeispiel und dessen Format in R und betrachten am Ende des Tutorials typische Formatierungs-Optionen (z.B. Farbenwahl, Schriftgrößen, ...). Im Verlauf des Tutorials bauen wir den Code schrittweise auf.
- Wenn du bereits erste Erfahrungen mit ggplot2 hast, kannst du auch direkt die finale Beispielgrafik ansehen und Darstellingsdetails durch die markierten Hotspots in Erfahrung bringen.
- Vielleicht findest du deine Frage zu Grafiken in R und die entsprechende Antwort auch im FAQ wieder.
Grafiken designen
Je nach Art der Daten (z.B. kategoriale vs. stetige Variablen, ...) sind unterschiedliche Arten von Grafiken geeignet. Hier findest du Inspiration für Visualisierungsmöglichkeiten und entsprechende Code-Beispiele für ggplot2 und weiterführende, auf ggplot aufbauende Packages. In diesem Glossarbeitrag findest du außerdem Hinweise, was bei der Darstellung von Fehlerbalken (insbesondere von Konfidenzintervallen) in Grafiken mit Punktschätzern (z.B. Mittelwerten) zu beachten ist sowie Daumenregel für deren Interpretation, beispielsweise in Bezug auf t-tests.

Beispielcode für typische Grafiken
Solltest du Beispielcode für übliche Grafiken suchen wirst du hier ebenfalls fündig. Manchmal hilft ein anderes Beispiel oder eine zweite Erklärung mit anderen Worten bei deinem Verständnis enorm.

Inspiration finden
Wenn du noch keine Idee hast, wie du die Vielzahl deiner Variablen möglichst effizient und dennoch aussagekräftig in einer Grafik darstellen möchtest, kannst du dir Inspiration holen. Zugleich findest du auch den zugehörigen Beispielcode, den du nur noch an deine Daten anpassen musst.
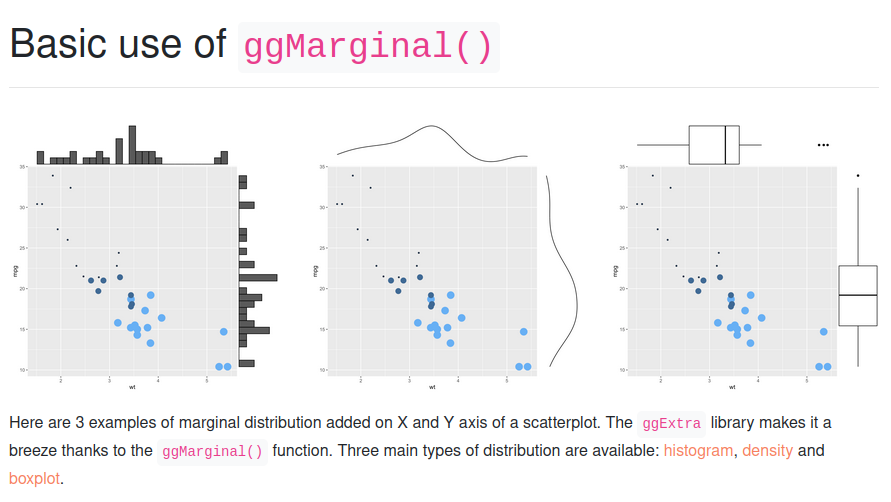
Erweiterungs-Packages für komplexere Grafiken
Für komplexere Grafiken, die häufig verwendet werden (z.B. Korrelogramme zur Visualisierung vieler Korrelationen), gibt es häufig Packages, die die Anwendung dieser komplexen Grafiken sehr erleichtern. Viele dieser Packages verwenden intern ggplot2 und schreiben für dich den komplexen Code, um deine Coding-Arbeit zu erleichtern.
-
Wenn du den Grafik-Code selbst ausprobieren möchtest, kannst du die im Tutorial verwendeten Daten einfach herunterladen und mit load("Beispieldaten.rda") in RStudio einlesen.
-
-
-
-
Wenn du die Beispiel-Grafiken selbst ausprobieren möchtest, kannst du die Daten einfach herunterladen und den Beispiel-Code in RStudio ausführen.
-
-
-
Die aktuellste Version des Cheat Sheets und weiterführende Informationen findest du außerdem auf der ggplot2-Homepage.
-
Wenn du lieber Grafiken in base R (ohne das Pakage ggplot2) erstellen möchtest, kannst du dir hier verschiedene Tutorials anschauen (beispielsweise für Liniendiagramme, o.a.).
-
-
-
-

Was ist das?
Hier findest du nützliche Hinweise zu Open Science Praktiken und Schreibtipps.
-
-
-

Konzeption und Zusammenstellung der Materialien: Salomé Li Keintzel, Kim-Laura Speck, Natascha Stahl, Marie Fuchs, Lea Degner, Constantin Wiegand, Amelie Jägersberg, Moritz Ehrnstraßer, Sarah Kleiner, Sarai Borchardt
Förderung: Dieser Kurs wurde durch eine Zentrale Lehrförderung der Universität Kassel ermöglicht und vom Servicecenter Lehre (Dr. Serap Uzunbacak; Hsiang-Chin Wang aus dem Projekt HessenHub) didaktisch begleitet.
Ansprechperson für allgemeine Anliegen zum Kurs: Salomé Li Keintzel (slkeintzel@uni-kassel.de; FG Psychologische Forschungsmethoden), Prof. Dr. Florian Scharf (florian.scharf@uni-kassel.de; FG Psychologische Forschungsmethoden)
Verwendungsrechte: folgt
-
-



