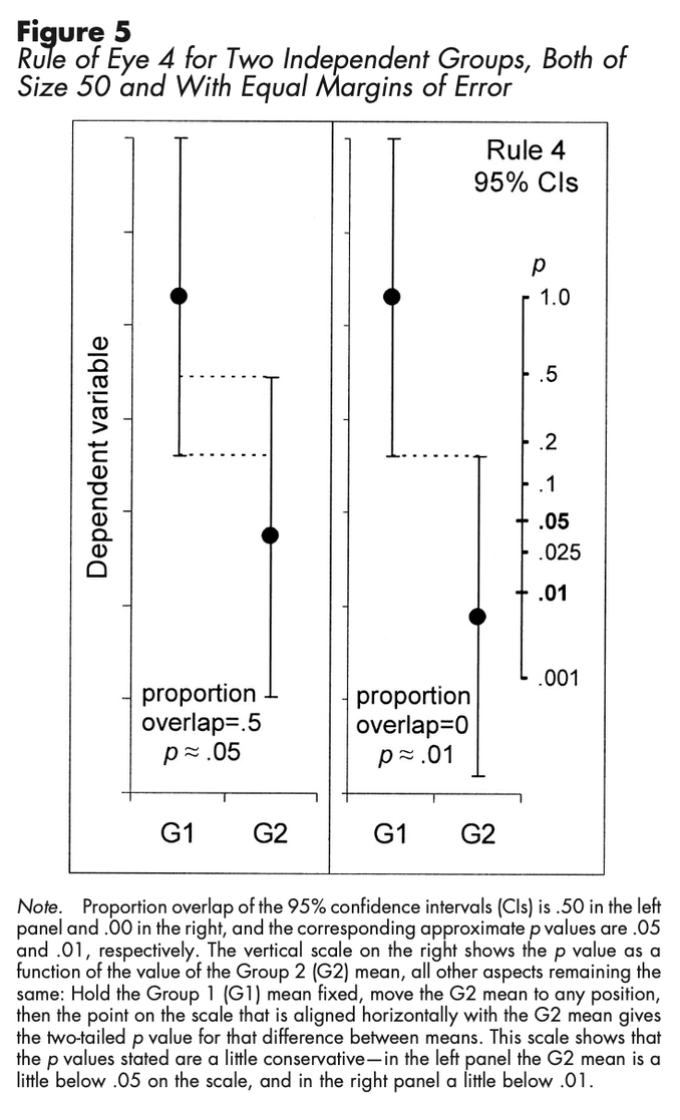
Der Einsatz von Intervallschätzern in der psychologischen Forschung hat das Potenzial die Kommunikation von Ergebnissen zu verbessern. Konfidenzintervalle haben unter anderem den Vorteil, dass sie in Relation zu p-Werten aus der klassischen inferenzstatistischen Nullhypothesen-Signifikanztestung (NHST) stehen und gleichzeitig dabei helfen können, über dichotome Entscheidungen beim NHST (p < .05 vs. p > .05) hinauszugehen. Dafür sind Konfidenzintervalle gerade in Grafiken nützlich, insbesondere wenn direkt die interessierenden Punktschätzer und deren Konfidenzintervalle dargestellt werden (beispielsweise bei einem t-Test direkt die geschätzte Differenz zwischen zwei Gruppen und das Konfidenzintervall der Differenz). Dazu sollte Klarheit darüber geschaffen werden, wie die Grafik zu verstehen ist, d.h. ob Konfidenzintervalle, Standardfehler oder Standardabweichungen als Fehlerbalken dargestellt sind und auf Basis welchen Forschungsdesigns die Ergebnisse entstanden sind (bspw. ob es Messwiederholung gab). Ist das gegeben, können Daumenregeln zur (visuellen) Interpretation von Ergebnisgrafiken anhand von Konfidenzintervallen angewendet werden: u.a. (1) Das Konfidenzintervall kann so verstanden werden, dass Werte innerhalb des Intervalls plausibel erscheinen und Werte außerhalb des Intervalls eher nicht (dabei sollte aber nicht zu viel Gewicht darauf gelegt werden, ob ein interessierender Wert gerade nicht oder gerade schon im Konfidenzintervall enthalten ist, um Entscheidungen nicht zu stark zu Dichotomisieren), (2) die Fehlermarge (Hälfte der Länge des gesamten Konfidenzintervalls) kann als Indikator für die Präzision der Studie verstanden werden (größere Fehlermarge, ungenauere Schätzung), (3) im Fall von unabhängigen Stichproben ist p < .05 wenn sich die 95%-Konfidenzintervalle der beiden Mittelwerte nicht mehr als die Hälfte der durchschnittlichen Fehlermarge überschneiden (siehe Abbildung; das gilt nur sofern die Stichprobengröße in jeder Gruppe mindestens 10 ist und die beiden Fehlermargen sich nicht mehr als um den Faktor 2 unterscheiden), (4) dies ist nicht auf abhängige Stichproben übertragbar, hier sollte man sich auf den Mittelwert der Differenzen und dessen Konfidenzintervall konzentrieren (interessant ist hier, inwiefern die 0 im Konfidenzintervall eingeschlossen ist), (5) auch im Kontext von Konfidenzintervallen ist es notwendig über die praktische Relevanz und Größe eines etwaigen Effekts nachzudenken anstatt sich nur auf die statistisch Signifikanz/Bedeutung zu fokussieren (beispielsweise bei einem unabhängigen t-test ist also nicht nur die Überlappung der Konfidenzintervalle zu achten, sondern auch, inwiefern der Unterschied zwischen den beiden Gruppen überhaupt auch eine praktische Relevanz hat). Interpretationshilfen gibt es auch für Standardfehler als Fehlerbalken, wobei Konfidenzintervalle im Kontext von Ergebnisgrafiken Vorteile gegenüber Standardfehler-Balken mit sich bringen. Übergreifend besteht das Problem, dass es nicht in allen Fällen einfach möglich ist, überhaupt ein Konfidenzintervall zu berechnen und die grafische Ergebnisdarstellung bei komplexeren Studiendesigns schnell schwierig und unübersichtlich wird.
Quelle/Noch mehr zu Konfidenzintervallen:
Cumming, G. & Finch, S. (2005b). Inference by Eye: Confidence Intervals and How to Read Pictures of Data. American Psychologist, 60(2), 170–180. https://doi.org/10.1037/0003-066x.60.2.170